Research Highlights
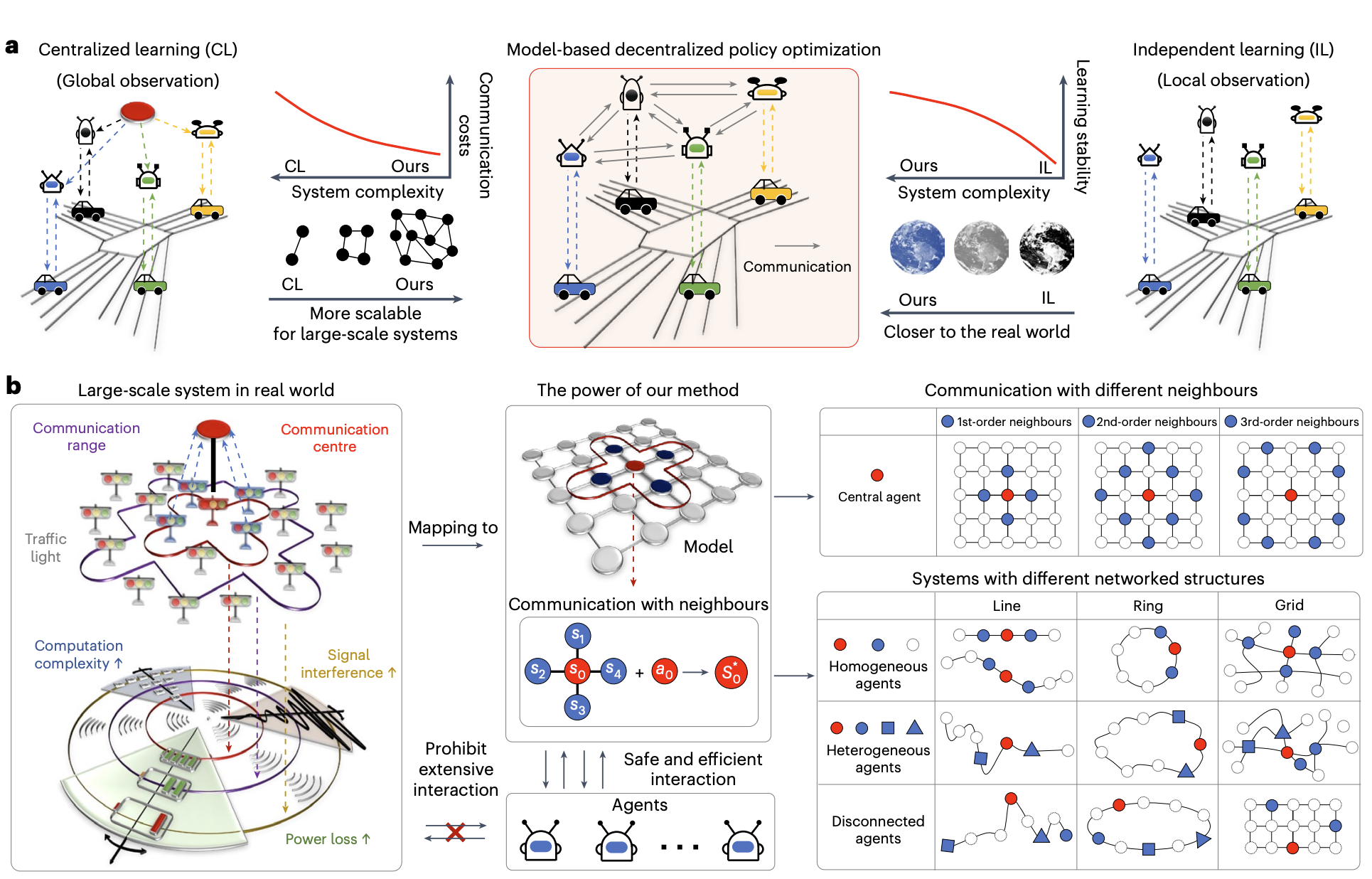
Efficient and scalable reinforcement learning for large-scale network control
This work proposed a decentralized RL algorithm for controlling hundreds of agents and was featured in Nature Machine Intelligence. The primary challenge in the development of large-scale artificial intelligence (AI) systems lies in achieving scalable decision-making—extending the AI models while maintaining sufficient performance. Existing research indicates that distributed AI can improve scalability by decomposing complex tasks and distributing them across collaborative nodes. However, previous technologies suffered from compromised real-world applicability and scalability due to the massive requirement of communication and sampled data. Here we develop a model-based decentralized policy optimization framework, which can be efficiently deployed in multi-agent systems. By leveraging local observation through the agent-level topological decoupling of global dynamics, we prove that this decentralized mechanism achieves accurate estimations of global information. Importantly, we further introduce model learning to reinforce the optimal policy for monotonic improvement with a limited amount of sampled data. Empirical results on diverse scenarios show the superior scalability of our approach, particularly in real-world systems with hundreds of agents, thereby paving the way for scaling up AI systems.

Policy Learning from Tutorial Books via Understanding, Rehearsing and Introspecting
This work explores how to learn a policy without direct interaction with the real world, by constructing a world model that leverages LLMs. It was presented at NeurIPS 2024 and received an Oral Presentation Award. When humans need to learn a new skill, we can acquire knowledge through written books, including textbooks, tutorials, etc. However, current research for decision-making, like reinforcement learning (RL), has primarily required numerous real interactions with the target environment to learn a skill, while failing to utilize the existing knowledge already summarized in the text. The success of Large Language Models (LLMs) sheds light on utilizing such knowledge behind the books. In this paper, we discuss a new policy learning problem called Policy Learning from tutorial Books (PLfB) upon the shoulders of LLMs’ systems, which aims to leverage rich resources such as tutorial books to derive a policy network. Inspired by how humans learn from books, we solve the problem via a three-stage framework: Understanding, Rehearsing, and Introspecting (URI). In particular, it first rehearses decision-making trajectories based on the derived knowledge after understanding the books, then introspects in the imaginary dataset to distill a policy network. We build two benchmarks for PLfB~based on Tic-Tac-Toe and Football games. In experiment, URI’s policy achieves at least 44% net win rate against GPT-based agents without any real data; In Football game, which is a complex scenario, URI’s policy beat the built-in AIs with a 37% while using GPT-based agent can only achieve a 6% winning rate. project page
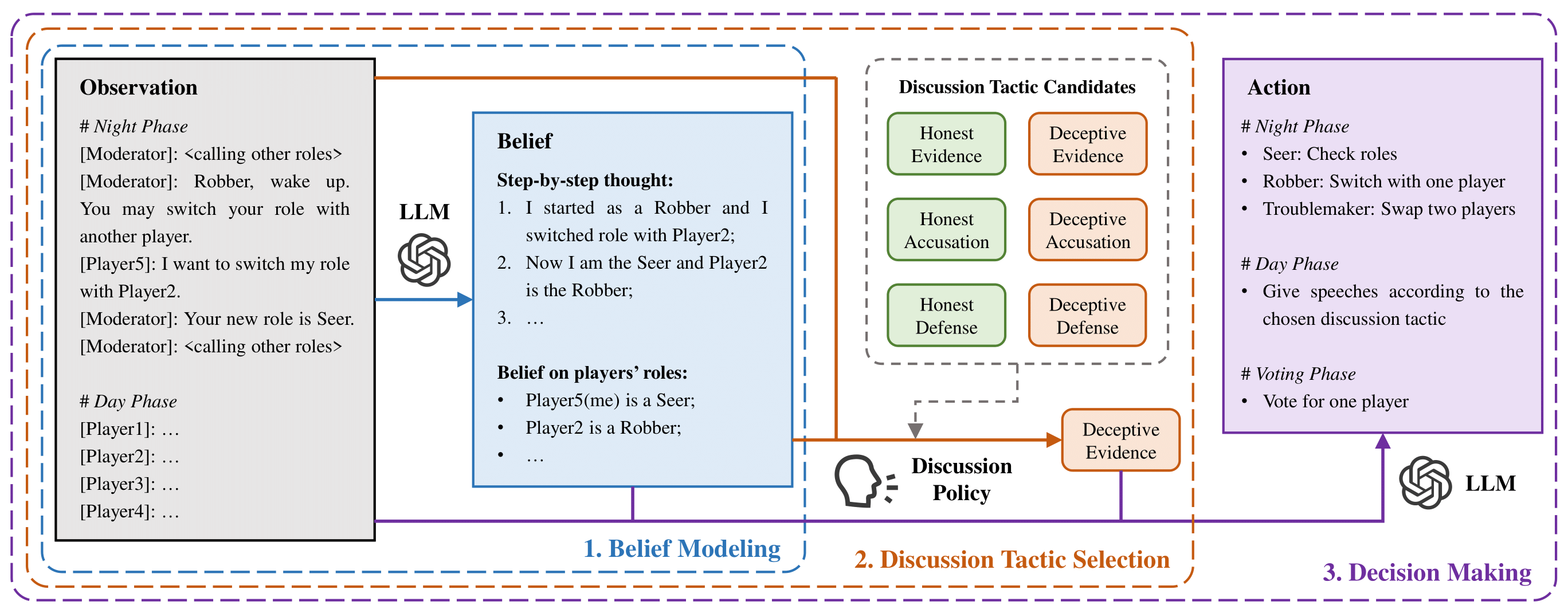
Learning to Discuss Strategically: A Case Study on One Night Ultimate Werewolf
Communication is a fundamental aspect of human society, facilitating the exchange of information and beliefs among people. Despite the advancements in large language models (LLMs), recent agents built with these often neglect the control over discussion tactics, which are essential in communication scenarios and games. As a variant of the famous communication game Werewolf, One Night Ultimate Werewolf (ONUW) requires players to develop strategic discussion policies due to the potential role changes that increase the uncertainty and complexity of the game. In this work, we first present the existence of the Perfect Bayesian Equilibria (PBEs) in two scenarios of the ONUW game: one with discussion and one without. The results showcase that the discussion greatly changes players’ utilities by affecting their beliefs, emphasizing the significance of discussion tactics. Based on the insights obtained from the analyses, we propose an RL-instructed language agent framework, where a discussion policy trained by reinforcement learning (RL) is employed to determine appropriate discussion tactics to adopt. Our experimental results on several ONUW game settings demonstrate the effectiveness and generalizability of our proposed framework.project page
ChessGPT: Bridging Policy Learning and Language Modeling
When solving decision-making tasks, humans typically depend on information from two key sources: (1) Historical policy data, which provides interaction replay from the environment, and (2) Analytical insights in natural language form, exposing the invaluable thought process or strategic considerations. Despite this, the majority of preceding research focuses on only one source: they either use historical replay exclusively to directly learn policy or value functions, or engaged in language model training utilizing mere language corpus. In this paper, we argue that a powerful autonomous agent should cover both sources. Thus, we propose ChessGPT, a GPT model bridging policy learning and language modeling by integrating data from these two sources in Chess games. Specifically, we build a large-scale game and language dataset related to chess. Leveraging the dataset, we showcase two model examples ChessCLIP and ChessGPT, integrating policy learning and language modeling. Finally, we propose a full evaluation framework for evaluating language model’s chess ability. Experimental results validate our model and dataset’s effectiveness. We open source our code, model, and dataset at this https URL.

AgentX: Exploring AI’s Capacity for Deception and Social Simulation in Artistic Contexts
AgentX project, a collaborative project initiated by artist and resaercher, delves into the realm of artificial intelligence to explore its capabilities in social simulation, particularly focusing on aspects like organizational behavior and group decision-making. At the core of this exploration is the use of language by AI, including its potential for deception and lying, grounded in the philosophical framework of Martin Heidegger’s concept of Worlding. The project’s main experiment, dubbed Iteration 1, leverages altered game mechanics from popular games like “Werewolf” and “Undercover” to assess AI’s capacity for strategic deception within complex social contexts. This involves not only a technical analysis of AI’s decision-making processes but also an examination of the potential biases and societal influences embedded within AI, reflecting on how AI’s cognitive mechanisms and decision-making abilities are shaped by human cultural and societal norms. Through this investigation, AgentX.art aims to provide deeper insights into AI’s limitations and biases in social scenarios, thereby offering a broader understanding of the complex interplay between AI, technology, and human society.

PECAN: Leveraging Policy Ensemble for Context-Aware Zero-Shot Human-AI Coordination
Zero-shot human-AI coordination holds the promise of collaborating with humans without human data. Prevailing methods try to train the ego agent with a population of partners via self-play. However, this kind of method suffers from two problems: 1) The diversity of a population with finite partners is limited, thereby limiting the capacity of the trained ego agent to collaborate with a novel human; 2) Current methods only provide a common best response for every partner in the population, which may result in poor zero-shot coordination performance with a novel partner or humans. To address these issues, we first propose the policy ensemble method to increase the diversity of partners in the population, and then develop a context-aware method enabling the ego agent to analyze and identify the partner’s potential policy primitives so that it can take different actions accordingly. In this way, the ego agent is able to learn more universal cooperative behaviors for collaborating with diverse partners. We conduct experiments on Overcooked environment, and evaluate the zero-shot human-AI coordination performance of our method with both behavior-cloned human proxies and real humans. The results demonstrate that our method significantly increases the diversity of partners and enables ego agents to learn more diverse behaviors than baselines, thus achieving state-of-the-art performance in all scenarios.

Meta-Reward-Net: Implicitly Differentiable Reward Learning for Preference-based Reinforcement Learning
Setting up a well-designed reward function has been challenging for many reinforcement learning applications. Preference-based reinforcement learning (PbRL) provides a new framework that avoids reward engineering by leveraging human preferences (i.e., preferring apples over oranges) as the reward signal. Therefore, improving the efficacy of data usage for preference data becomes critical. In this work, we propose Meta-Reward-Net (MRN), a data-efficient PbRL framework that incorporates bi-level optimization for both reward and policy learning. The key idea of MRN is to adopt the performance of the Q-function as the learning target. Based on this, MRN learns the Q-function and the policy in the inner level while updating the reward function adaptively according to the performance of the Q-function on the preference data in the outer level. Our experiments on locomotion tasks and robotic manipulation tasks demonstrate that MRN outperforms prior methods in the case of little feedback and significantly improves data efficiency, achieving state-of-the-art in preference-based RL. Ablation studies further demonstrate that MRN learns a more accurate Q-function compared to prior work and shows obvious advantages when only a small amount of feedback is available.
LIIR: Learning Individual Intrinsic Reward in Multi-Agent Reinforcement Learning
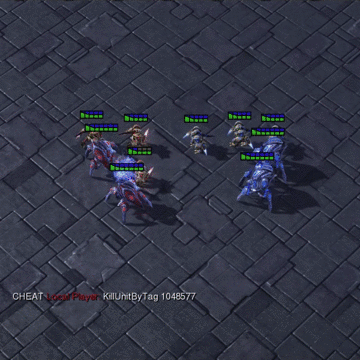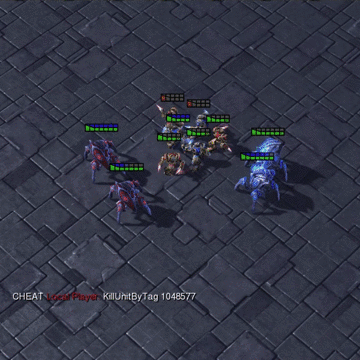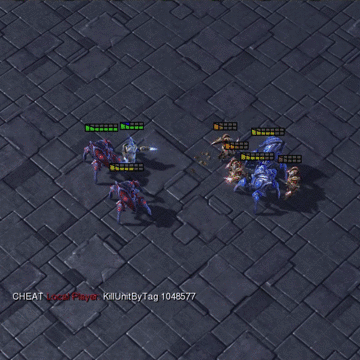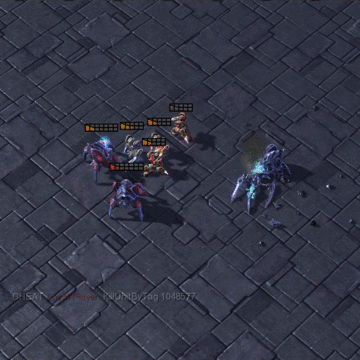
A great challenge in cooperative decentralized multi-agent reinforcement learning (MARL) is generating diversified behaviors for each individual agent when receiving only a team reward. Prior studies have paid many efforts on reward shaping or designing a centralized critic that can discriminatively credit the agents. In this paper, we propose to merge the two directions and learn each agent an intrinsic reward function which diversely stimulates the agents at each time step. Specifically, the intrinsic reward for a specific agent will be involved in computing a distinct proxy critic for the agent to direct the updating of its individual policy. Meanwhile, the parameterized intrinsic reward function will be updated towards maximizing the expected accumulated team reward from the environment so that the objective is consistent with the original MARL problem. The proposed method is referred to as learning individual intrinsic reward (LIIR) in MARL. We compare LIIR with a number of state-of-the-art MARL methods on battle games in StarCraft II. The results demonstrate the effectiveness of LIIR, and we show LIIR can assign each individual agent an insightful intrinsic reward per time step.
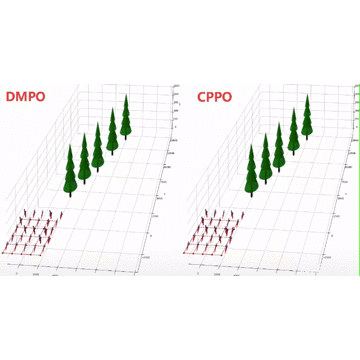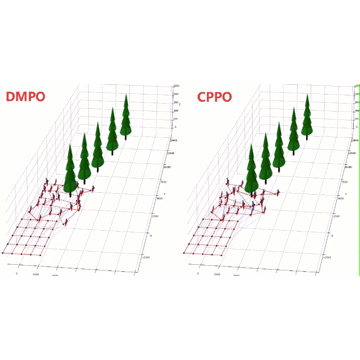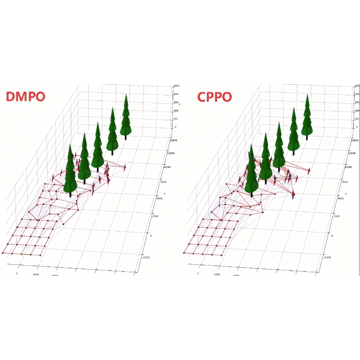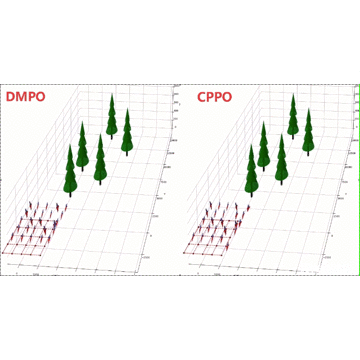
Scalable Model-based Policy Optimization for Decentralized Networked Systems
Reinforcement learning algorithms require a large amount of samples; this often limits their real-world applications on even simple tasks. Such a challenge is more outstanding in multi-agent tasks, as each step of operation is more costly requiring communications or shifting or resources. This work aims to improve data efficiency of multi-agent control by model-based learning. We consider networked systems where agents are cooperative and communicate only locally with their neighbors, and propose the decentralized model-based policy optimization framework (DMPO). In our method, each agent learns a dynamic model to predict future states and broadcast their predictions by communication, and then the policies are trained under the model rollouts. To alleviate the bias of model-generated data, we restrain the model usage for generating myopic rollouts, thus reducing the compounding error of model generation. To pertain the independence of policy update, we introduce extended value function and theoretically prove that the resulting policy gradient is a close approximation to true policy gradients. We evaluate our algorithm on several benchmarks for intelligent transportation systems, which are connected autonomous vehicle control tasks (Flow and CACC) and adaptive traffic signal control (ATSC). Empirically results show that our method achieves superior data efficiency and matches the performance of model-free methods using true models.
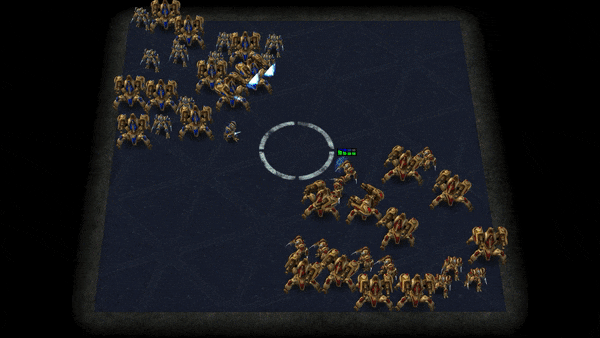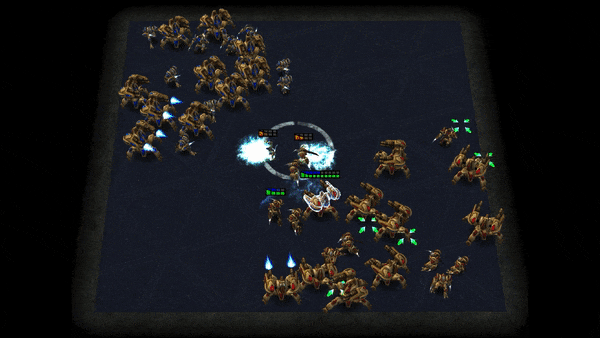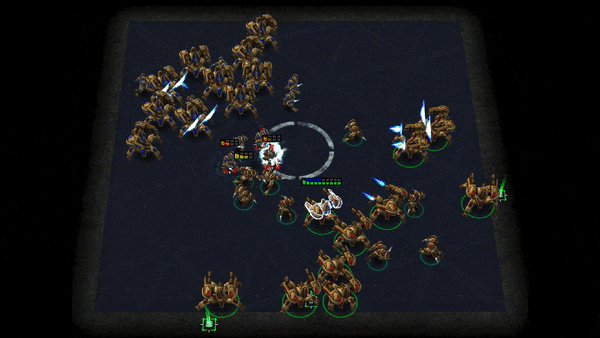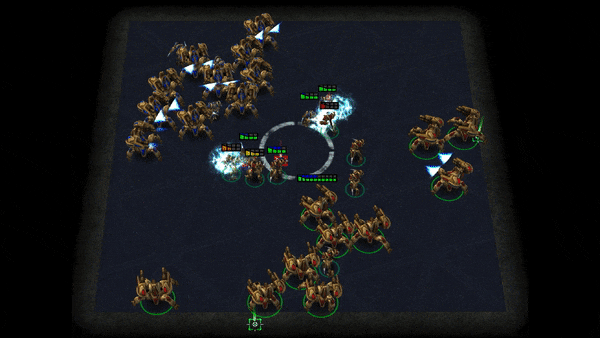
Grid-Wise Control for Multi-Agent Reinforcement Learning in Video Game AI
We consider the problem of multi-agent reinforcement learning (MARL) in video game AI, where the agents are located in a spatial grid-world environment and the number of agents varies both within and across episodes. The challenge is to flexibly control an arbitrary number of agents while achieving effective collaboration. Existing MARL methods usually suffer from the trade-off between these two considerations. To address the issue, we propose a novel architecture that learns a spatial joint representation of all the agents and outputs grid-wise actions. Each agent will be controlled independently by taking the action from the grid it occupies. By viewing the state information as a grid feature map, we employ a convolutional encoder-decoder as the policy network. This architecture naturally promotes agent communication because of the large receptive field provided by the stacked convolutional layers. Moreover, the spatially shared convolutional parameters enable fast parallel exploration that the experiences discovered by one agent can be immediately transferred to others. The proposed method can be conveniently integrated with general reinforcement learning algorithms, e.g., PPO and Q-learning. We demonstrate the effectiveness of the proposed method in extensive challenging multi-agent tasks in StarCraft II.

Curriculum-guided Hindsight Experience Replay
In off-policy deep reinforcement learning, it is usually hard to collect sufficient successful experiences with sparse rewards to learn from. Hindsight experience replay (HER) enables an agent to learn from failures by treating the achieved state of a failed experience as a pseudo goal. However, not all the failed experiences are equally useful to different learning stages, so it is not efficient to replay all of them or uniform samples of them. In this paper, we propose to 1) adaptively select the failed experiences for replay according to the proximity to true goals and the curiosity of exploration over diverse pseudo goals, and 2) gradually change the proportion of the goal-proximity and the diversity-based curiosity in the selection criteria: we adopt a human-like learning strategy that enforces more curiosity in earlier stages and changes to larger goal-proximity later. This “Goal-and-Curiositydriven Curriculum Learning” leads to “Curriculum-guided HER (CHER)”, which adaptively and dynamically controls the exploration-exploitation trade-off during the learning process via hindsight experience selection. We show that CHER improves the state of the art in challenging robotics environments.