Code
M3HF: Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality
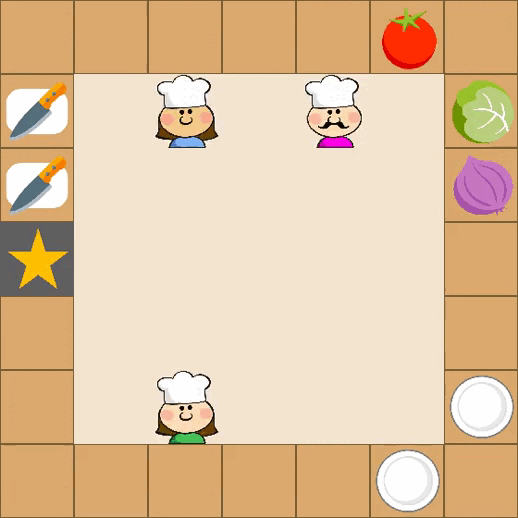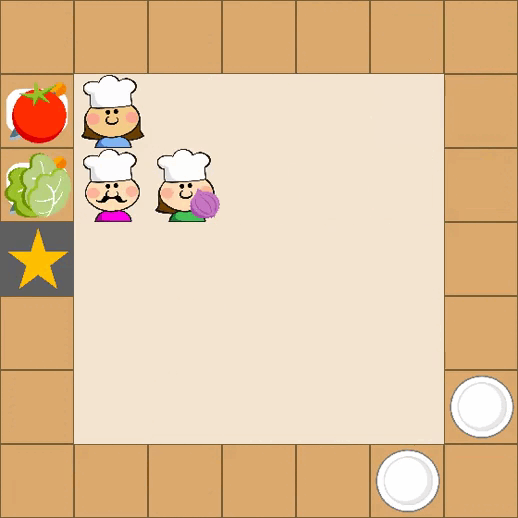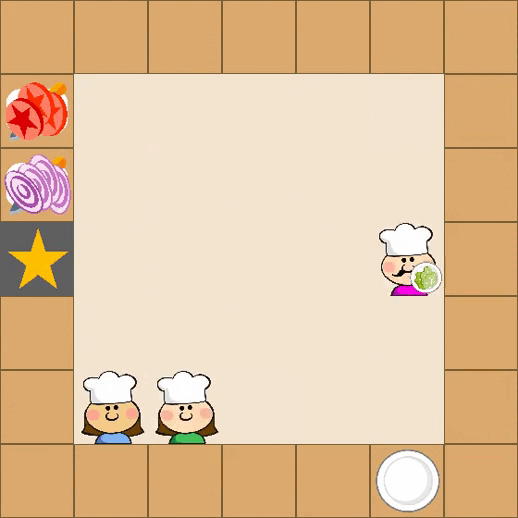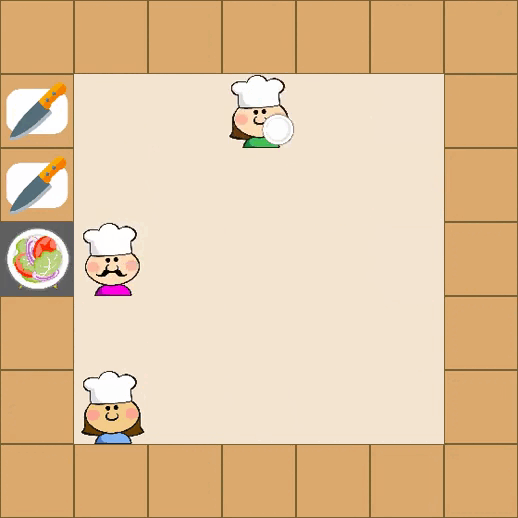
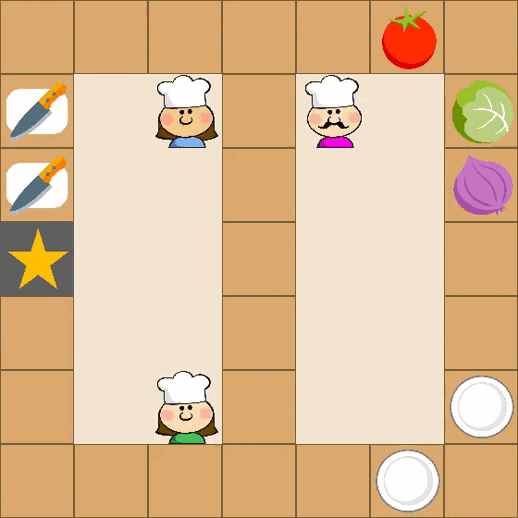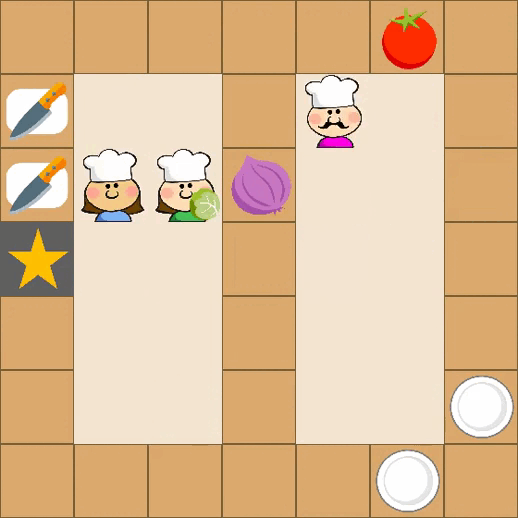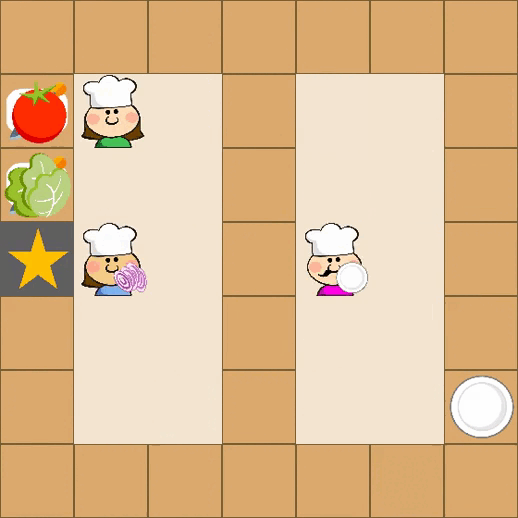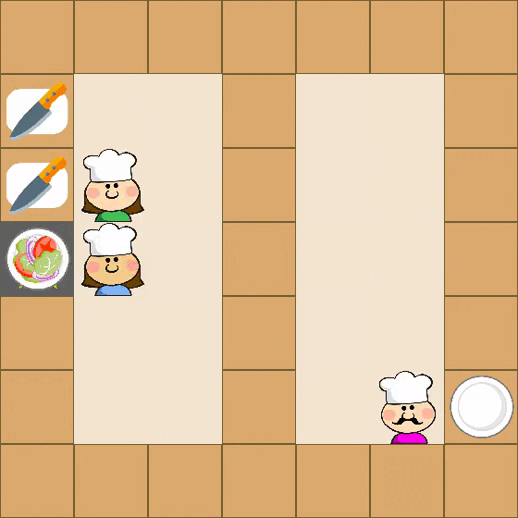
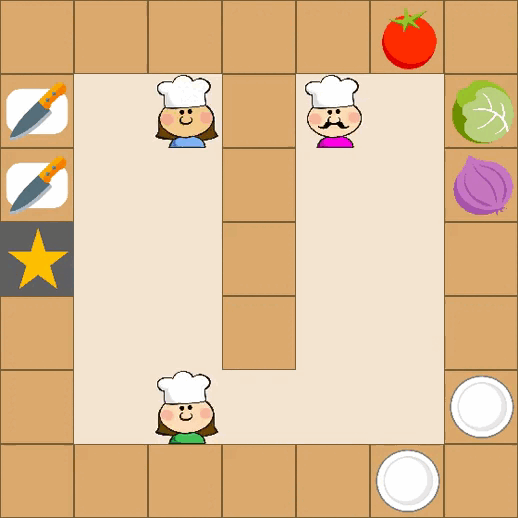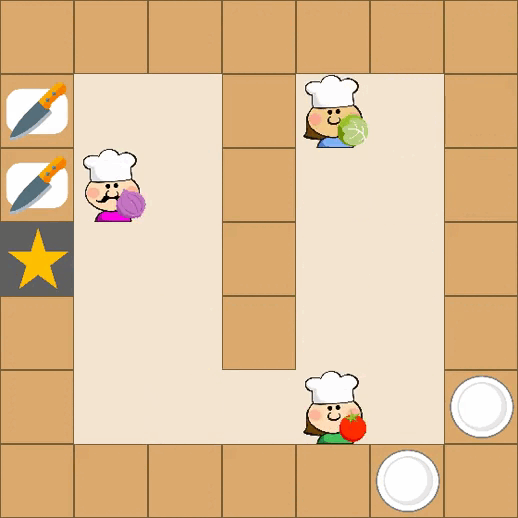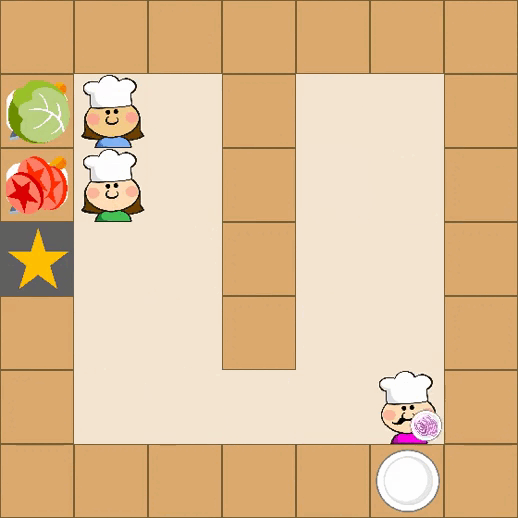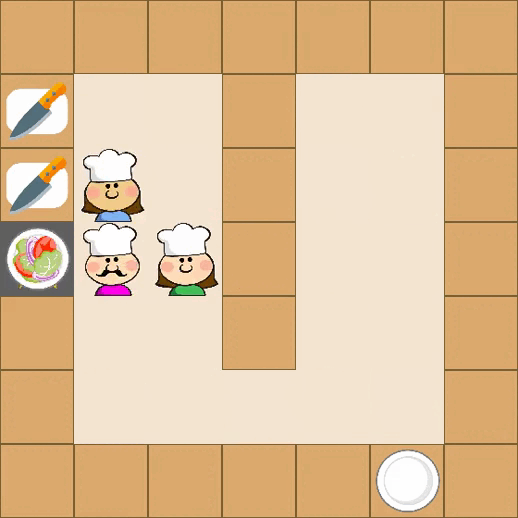
Designing effective reward functions in multi-agent reinforcement learning (MARL) is a significant challenge, often leading to suboptimal or misaligned behaviors in complex, coordinated environments. We introduce Multi-agent Reinforcement Learning from Multi-phase Human Feedback of Mixed Quality (M3HF) — a novel framework that integrates multi-phase human feedback of mixed quality into the MARL training process. Our approach enables the integration of nuanced human insights across varying levels of quality, enhancing the interpretability and robustness of multi-agent cooperation. Empirical results in challenging environments demonstrate that M3HF significantly outperforms state-of-the-art methods, effectively addressing the complexities of reward design in MARL and enabling broader human participation in the training process.
SocialJax: a suite of sequential social dilemma environments for multi-agent RL in JAX

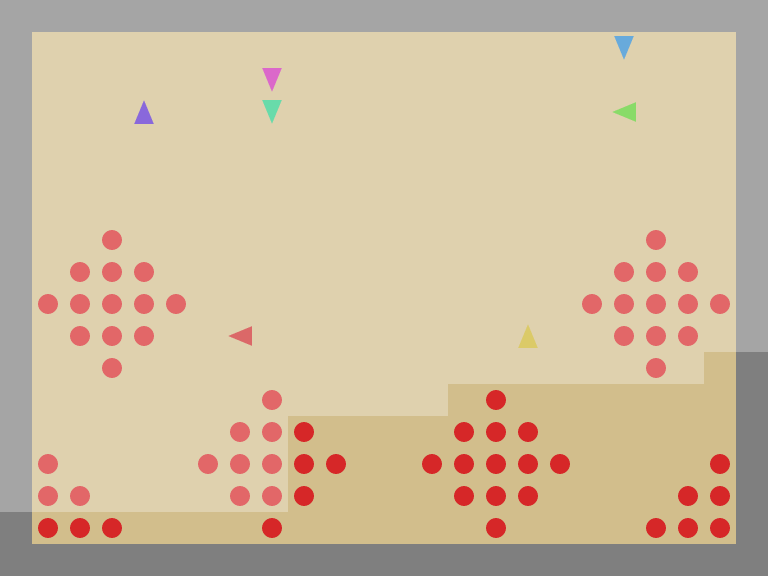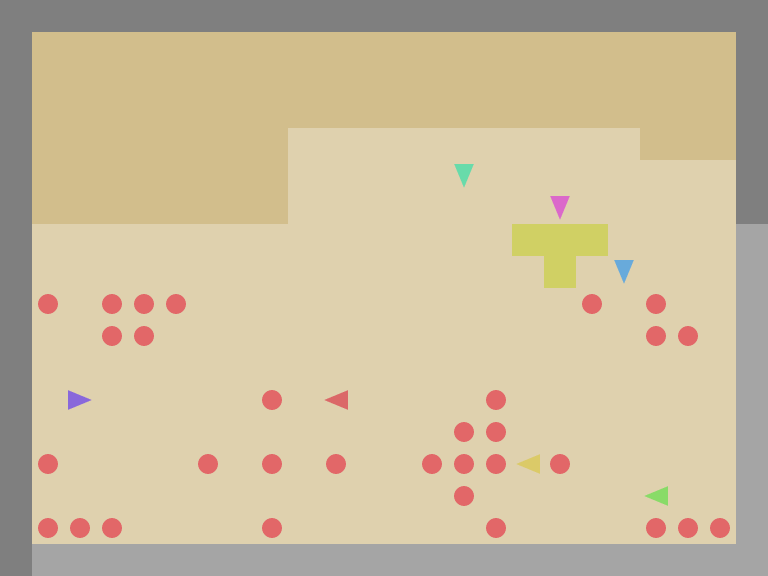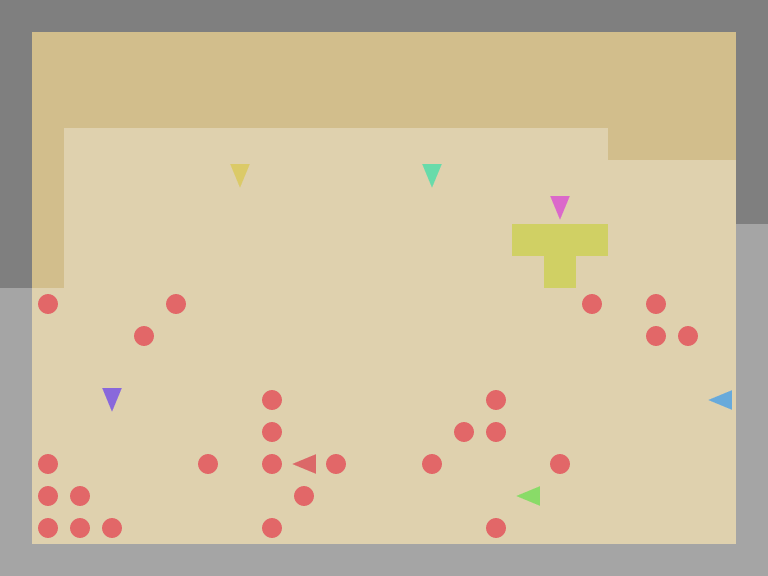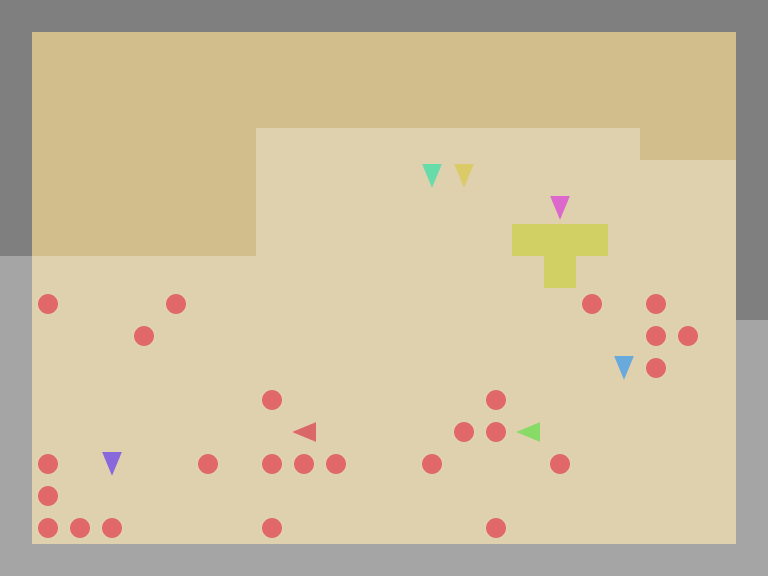



It provides a collection of social dilemma environments and baseline algorithms implemented in JAX, offering user-friendly interfaces combined with the efficiency of hardware acceleration. By achieving remarkable speed-ups over traditional CPU-based implementations, SocialJax significantly reduces the experiment runtime. In addition, its unified codebase consolidates a diverse range of social dilemma environments into a standardized framework, facilitating consistent and efficient experimentation and greatly benefiting future research on social dilemmas.